
The modern enterprise is a vast, dynamic and complex digital ecosystem where data constantly moves through cloud platforms, SaaS applications, analytics environments, BI dashboards, collaboration tools, remote endpoints, AI systems and downstream data pipelines.
Records proliferate as they are captured and retained within the many systems, services and applications used to process them.
The diversity and dynamic nature of modern enterprise data environments means that traditional risk mitigation methods are unable to keep pace with identifying and managing risks as they emerge.
What is next-generation risk?
Next-generation risk refers to the emerging and evolving data risks created by these modern environments, advanced analytics, AI-enabled systems and future cryptographic threats.
These risks are different because they are not confined to a single application, network boundary or technology stack. They emerge as sensitive data moves across cloud platforms, SaaS applications, on-premises systems, remote endpoints, BI environments, AI pipelines and third-party workflows.
They also have a longer and more complex risk horizon. Some risks are active now, such as data exposure through generative AI prompts, unauthorized SaaS storage or unmanaged analytics extracts. Others are future-facing but already require action, such as post-quantum cryptography migration and “harvest now, decrypt later” threats targeting long-lived sensitive data.
What is next-generation risk mitigation?
Next-generation risk mitigation is a data-aware approach to reducing security, privacy and compliance risk across modern enterprise environments. It focuses on discovering sensitive data, understanding exposure, prioritizing risk and reducing unnecessary access, retention and insecure storage across cloud, SaaS, on-premises, remote-working, AI and analytics ecosystems.
This approach aligns with the broader shift from perimeter-focused security to data-centric models like zero trust. The zero-trust security model eliminates implicit trust and instead requires continuous verification to determine access and other system responses.
 Next-generation risk mitigation takes this further by focusing risk management at source: the data itself. Rather than relying only on asset inventories, access reviews or point-in-time assessments, it asks whether organizations can identify sensitive data wherever it exists, understand the context of its exposure and take action before that exposure becomes a breach, compliance failure or operational weakness.
Next-generation risk mitigation takes this further by focusing risk management at source: the data itself. Rather than relying only on asset inventories, access reviews or point-in-time assessments, it asks whether organizations can identify sensitive data wherever it exists, understand the context of its exposure and take action before that exposure becomes a breach, compliance failure or operational weakness.
Why traditional risk mitigation is under pressure
Many risk programs still depend heavily on asset inventories, access reviews, security questionnaires and point-in-time assessments. These remain important, but they often miss the way sensitive data actually behaves across a modern enterprise.
Enterprise data is more mobile than ever before, transiting several systems in a single process. Modern working methods have driven a shift from on-premises, office-based operations to remote teams collaborating via cloud and SaaS services several hundred times a day.
Organizations depend on data to function; whether that’s processing an online shopping order, managing customer service, manufacturing goods or developing software and applications. Increasingly, they also rely on BI, AI and analytics pipelines for advanced metrics and decision making.
All these processes create copies, extracts, indexes and derived datasets, further expanding the data footprint and potential for unmanaged exposure.
That exposure can only be managed effectively with data-level evidence, answering questions like:
-
What sensitive data do we have and where is it stored?
-
Who or what can access it?
-
How long have we had it, and how long do we need to keep it?
-
Has it been copied and where to?
-
What operational processes and workflows use it?
-
What is the control environment for that data?
Without this insight, it’s impossible to make sure that the highest priority risks are being treated.
Modern data architectures have expanded the risk surface
Business intelligence, AI and analytics programs depend on data movement. Data is extracted, transformed, enriched, indexed, joined and reused to create business insight. That activity creates value, but it also creates additional locations where sensitive information may exist outside the original system of record.
A data record that is created in a production system is passed into a warehouse, analytics dashboard or training dataset. In AI-enabled environments, it can also appear in prompts, RAG pipelines and connected knowledge stores.
As a result, the most important exposure may not be in the primary application. It may be in one of the additional locations where it also now lives, that may sit outside the scope of the original controls designed to protect it.
“BI, AI and analytics pipelines increase data risk because they often copy, transform and reuse sensitive data outside its original system of record. This creates additional locations where data must be discovered, classified, protected and monitored.”
Mixed cloud, SaaS, on-premises and remote environments make visibility harder
Most organizations now operate across mixed digital and physical environments. 73% of organizations operate hybrid estates, and in the US just 22% of businesses are fully on-site.
The growing sensitive data sprawl covers public cloud storage, SaaS platforms, on-premises databases, endpoints, productivity tools, backup systems, file shares and structured applications. Remote working has also contributed to increasing local downloads, informal file sharing and reliance on digital collaboration.
While zero-trust principles are effective for cloud-native and hybrid data environments, their reliance on identity doesn’t solve the full data-risk problem. As well as identities - of users or systems – zero-trust demands the knowledge of the data assets those identities can reach. This is facilitated by asset labelling and maintaining up-to-date information about who and what is authorized to access it.
Along with the fragmentation of environments comes the distribution of accountability and ownership. Businesses may be more connected than ever before, but without centralized oversight of key assets distributed between teams and across environments, platforms and tools.
Post-quantum cryptography migration is an issue for today
Quantum computing threatens widely used public-key cryptographic methods. CISA has stated that as quantum computing advances, it presents increasing risk to certain widely used encryption methods. It recommends organizations identify and catalog vulnerable systems as a first step to post-quantum migration.
While NIST has approved three Federal Information Processing Standards for PQC migration, the process for many businesses will be a complex, multi-year program through which they’ll need to identify, prioritize and migrate their cryptography. At the same time, managing dependencies and significant operational disruption.
Quantum computing threatens the security of current cryptographic algorithms, but those algorithms protect sensitive data. The nature of that data matters when it comes to prioritizing PQC migration. Long-lived data is the most at risk, since it’s likely to remain current after Q-day (the day the first algorithms are broken by quantum computers). This includes information like personal data, financial records, identity information, government data, trade secrets, regulated records and intellectual property.
PQC migration should be informed by data value, data lifespan and exposure (of the algorithm), prioritizing data with longer-term confidentiality requirements that will remain valuable to attackers over time.
Harvest now, decrypt later is already a present-day data risk
“Harvest now, decrypt later is a threat model where attackers capture encrypted data today with the expectation that future quantum computers may decrypt it. The risk is active now because data can be stolen before quantum decryption capability exists.”
Quantum risk is often discussed as a future issue, but “harvest now, decrypt later” makes it a very real and current threat.
Industry leaders have warned that attackers may be targeting valuable data stores today, regardless of its encryption, to keep until a quantum computer is available that can break the algorithm. If encrypted information is stolen today but would still be damaging if exposed in five, ten or twenty years, an organization has a current exposure even if quantum decryption is not yet practical.
Reducing unnecessary stores of long-lived sensitive data lowers the volume of information that could be harvested now and exposed later, and ensuring data is adequately protected are essential in mitigating the current threat.
Generative AI creates latent sensitive data exposure
The unprecedented adoption of generative AI within standard business processes has vastly shifted the way employees interact with company data.
Even where employees are reluctant to use company versions of tools like ChatGPT, Gemini, Claude or Copilot, they’re being embedded in collaboration platforms, productivity suites and across applications and analytics products. As a result, it's increasingly difficult to avoid interacting with AI during a normal workday.
Generative AI creates new data entry points, through prompts, uploaded files, browser extensions, APIs, connected drives or retrieval-augmented generation (RAG) workflows. Employees too may expose sensitive data unintentionally while using AI for summarization, analysis, coding or document drafting.
These tools create latent sensitive data exposure, with sensitive data transiting these workflows without triggering a security event. Once ingested, this data can form part of the model, exposed to future disclosure, and persists in logs, outputs, embeds and connected systems.
For this reason, it’s essential that ingestion sources are mapped for unauthorized sensitive data before AI access is provisioned, and ongoing monitoring of connected repositories is in place.
Agentic AI increases risk because access can become action
Agentic AI presents a different threat. Generative AI is typically human-driven through prompts and follow-on queries. Agentic AI systems can make decisions, call tools, retrieve records, update systems or trigger workflows on their own, with only limited human oversight. This means that an AI agent with access to sensitive records may also have the authority to act on them.
According to the Cloud Security Alliance, there is a growing gap between the adoption of AI agents and organizations’ readiness to manage them, highlighting concerns about excessive agency, use of static credentials, poor authorization and weak traceability.
Any data security and access management weaknesses become amplified once exposed to AI agents, especially when those agents are granted excessive permissions, functionality or autonomy.
Because these systems are introduced for efficiency, removing the human-factor in processes and decision-making, there is often only limited or significantly delayed oversight of their actions.
This is why it’s important to run frequent intelligence-based risk assessments evaluating what agents can access, decide, change and escalate, and identify early any sensitive data exposure.
The capabilities needed for next-generation risk mitigation
Next-gen risk mitigation requires a practical model connecting data intelligence with actionable outputs.
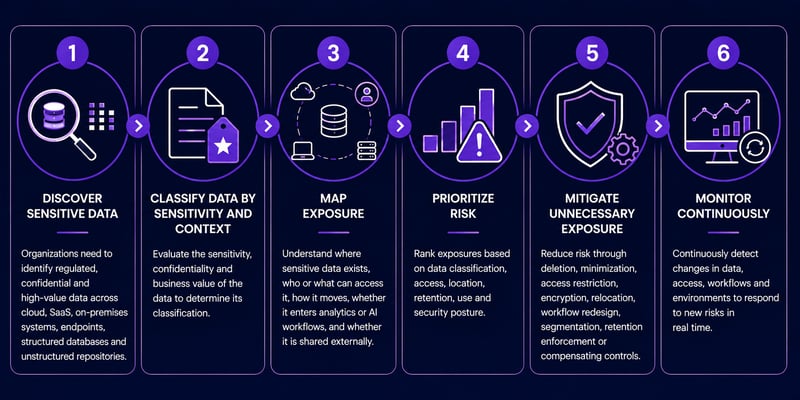
-
Discover sensitive data – Identify regulated, confidential and high-value data across cloud, SaaS, on-premises, endpoints, structured systems and unstructured repositories.
-
Classify data by sensitivity and context – Evaluate the sensitivity, confidentiality and value of data to determine its classification.
-
Map exposure – Assess where sensitive data exists, who or what can access it, how it moves and whether it enters analytics, AI, SaaS or third-party workflows.
-
Prioritize risk – Rank exposure based on sensitivity, access, location, retention period, cryptographic relevance, downstream use and business impact. Consider the security posture of the data environment.
-
Mitigate unnecessary exposure – Reduce risk through deletion, minimization, access restriction, encryption, relocation, workflow redesign or compensating controls.
-
Monitor continuously – Reassess exposure as data moves, systems change, employees adopt new tools and AI-enabled workflows expand.
Questions leaders need to ask
|
Data intelligence is becoming central to risk mitigation
As cloud, SaaS, AI, analytics and quantum-era risks converge, organizations need a clearer view of the data they hold, where it moves and how exposure changes over time. Companies like Ground Labs help organizations manage next-generation risk mitigation by identifying sensitive data, uncovering its control environment, ranking exposures and enabling remediation before risk becomes too hard to control or materialized as a security incident or data breach.
Frequently asked questions
What is next-generation risk mitigation?
Next-generation risk mitigation is a data-aware approach to reducing security, privacy and compliance risk across modern enterprise environments. It focuses on discovering sensitive data, understanding exposure, prioritizing risk and reducing unnecessary access or retention across cloud, SaaS, on-premises, AI and analytics ecosystems.
Why is sensitive data discovery important for risk mitigation?
Sensitive data discovery helps organizations understand where regulated, confidential or high-value data exists. Without that visibility, security and compliance teams may struggle to prioritize controls, reduce unnecessary exposure or prove that risk has been reduced.
What is harvest now, decrypt later?
Harvest now, decrypt later is a quantum threat model where attackers collect encrypted data today with the expectation that future quantum computers may decrypt it. This creates current risk for sensitive data that will be retained for more than the next three to five years.
How should organizations prepare for post-quantum risk?
Organizations should identify cryptographic dependencies, assess which data has long-term confidentiality requirements, and prioritize systems or repositories that protect sensitive information. Data discovery, classification and exposure management can support post-quantum migration planning.
How does generative AI increase data exposure risk?
Generative AI can increase exposure when sensitive data is entered into prompts, uploaded into AI tools, indexed for retrieval or reused in outputs. These risks can occur through user behavior, connected applications, APIs, assistants and retrieval-augmented generation (RAG) workflows.
Why is agentic AI a risk management concern?
Agentic AI is a risk management concern because it combines data access with autonomous decision-making or workflow execution without direct human interaction. Organizations need to understand what an agent can access, what it can change and where human approval is required.