
AI adoption is moving quickly across organizations of all sizes. Employees now use AI tools to summarize documents, analyze spreadsheets, write code, draft emails and search for internal information. Further, enterprise product vendors are embedding AI into their solutions, for support, data analysis, business intelligence and accelerated productivity.
The demand for data to train and support these models brings a new security challenge: without appropriate controls, sensitive data can be accessed by AI and shared before it can be reviewed and excluded by governance, privacy or security teams.
AI tools can access sensitive data through user prompts, file uploads, SaaS integrations, APIs and plugins, automation workflows and more. Preventing this data leakage starts before this information enters AI pipelines – discovering it before ingestion, reducing exposure and controlling access before AI systems interact with it.
This isn’t a theoretical risk: In Cost of a Data Breach 2025, IBM reported that AI adoption is outpacing governance with 13% of organizations suffering breaches of their AI models.
“The biggest AI data risk is often not the model itself. It is the sensitive data already sitting in places the model can access.”
How AI tools touch enterprise data
AI tools are integrated throughout operational workflows, as both standalone services and embedded features in business applications. Information enters AI systems through several mechanisms, depending on who (or what) is interacting with it and how.
This can include user prompts and file uploads, directly providing sensitive data as part of query inputs. SaaS integrations and APIs deliver system queries and prompts to generate outputs. Meanwhile, pipeline architectures define the flow of source data from enterprise systems and transformation into lakehouse storage for the AI model to analyze and respond.
The table below summarizes sensitive data entry points with real-world scenarios and the associated exposure risks.
| Sensitive data entry | Example | Data exposure risk | |
| User prompts | Employees enter sensitive data in prompts | Prompt text includes named customer contacts, commercial terms, support issues and contract renewal risks | Sensitive customer data and confidential account details may be retained and reused by the model |
| File uploads | Users upload files, source code or business system exports | A CSV export is uploaded for analysis, including customer names, transaction references and partial payment card data | Regulated or confidential data may enter the AI workflow without review or approval |
| Connected AI assistants | AI features embedded in productivity platforms and CRM data | AI assistants create summaries from sensitive information across all areas of the business | AI tools may present proprietary information, IP and PII data from connected systems in its outputs |
| APIs and integrations | Applications send data to AI models through API calls, third-party services, plug-ins, extensions and automation workflows | A support platform uses an AI API to summarize ticket histories before escalation | Sensitive data may move into AI services or logs through automated workflows without human oversight or approval |
| RAG and enterprise search | Retrieval-augmented generation (RAG) systems index internal documents for efficient responses | An internal AI search assistant indexes shared drives to help employees find policy documents and other HR-related information | Hidden or overexposed sensitive data may be presented to unauthorized users |
| Shadow AI | Employees use unsanctioned AI tools because they are fast or convenient, creating exposure outside approved processes | An employee uses a personal AI assistant to debug production code and pastes logs that include API keys, user IDs and system error details | Security teams have no visibility of the data shared and whether it was retained by the model for later disclosure |
Where data exposure happens in AI workflows
Data exposure can happen at multiple points throughout the AI workflow, from connected sources and user prompts to retrieval storage locations and model memory retention.
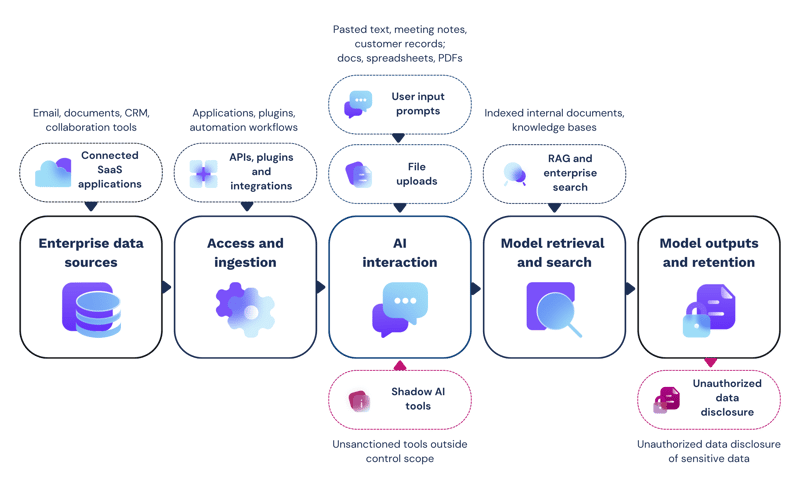
Where sensitive data enters the AI pipeline
Enterprise data sources
Sensitive data exists throughout an organization’s digital estate, in structured and unstructured formats, on-premises and in the cloud. Incidental stores of data are created daily, many of which remain hidden. Open file shares, cloud folders and collaboration tools are common data sources for AI tools. However, these locations may contain unmanaged sensitive data, which without prior discovery, enters the AI workflow without review and remediation.
Access and ingestion
Other ingestion sources include API connectors, plugins and integrations. Where these lack appropriate access controls, AI tools can inherit overly generous permissions and access sensitive information it later discloses to unauthorized users.
AI interaction
Employees are increasingly encouraged to use AI tools, enhancing their productivity and streamline operational processes. According to a 2026 report from KPMG, 88% of organizations have embedded AI agents in their workflows. Employees share company information and sensitive data in their AI prompts - in both authorized and unsanctioned tools. However, these prompts and any uploaded files are then analyzed by the tool, with some outputs stored for later retrieval.
Model retrieval and search
When data has been ingested by AI, it is transformed through a process that normalizes and indexes the data before storing it in a semi-structured lakehouse or RAG system for efficient retrieval later. Without prior sanitization, sensitive data can be ingested and retained by AI models and returned in outputs.
Model outputs and retention
AI-generated content can reproduce sensitive data in its outputs, either from stored memories, RAG systems or connected ingestion sources. Further, AI responses and system-generated logs can create new stores of sensitive data.
Discovery before AI ingestion
Data discovery is a crucial step in the AI adoption process that needs to take place before tools are given access to enterprise data assets or integrated with business systems.
Before enabling any AI tools, organizations must be able to answer the following key questions:
-
What sensitive data do we have?
-
Where does it reside?
-
Which repositories do we need to connect to AI tools?
-
What data do we need to classify, mask, remove or exclude before enabling AI access?
-
Which data sources do we need to review regularly for sensitive data after AI deployment?
Data discovery has to happen before any sensitive data enters the AI pipeline. This means before connecting file shares to productivity assistants; before indexing internal documents into a RAG system; before submitting training data into the tool; and before granting AI access to business systems via plugins, APIs and automation tools.
“AI tools can amplify existing data security gaps. If sensitive data is already overexposed in file shares, SaaS platforms or collaboration tools, AI can make that exposure easier to exploit.”
Five steps to safe AI with Enterprise Recon
Ground Labs Enterprise Recon helps organizations discover sensitive data before it reaches AI tools, and provides remediation capabilities to facilitate the adoption process.
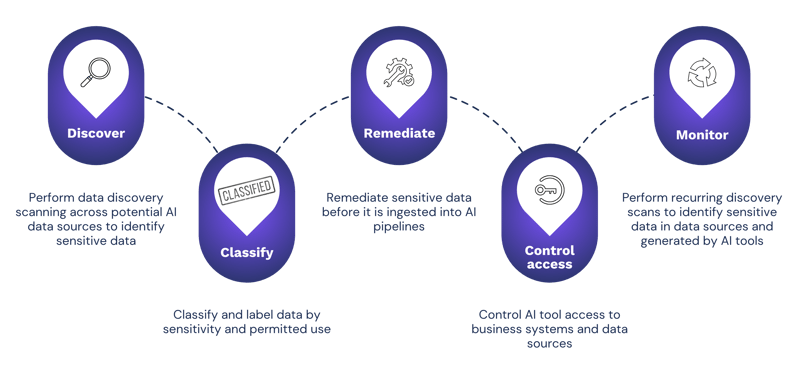
Five steps to safe AI with Enterprise Recon
-
Discover – Use Enterprise Recon to identify sensitive data within potential AI data sources, including on-premises and cloud-hosted systems, collaboration tools and end points.
-
Classify – Apply classification labeling to sensitive data with Enterprise Recon, to separate information that can be used freely by AI tools from data that needs additional control or sanitization before entering the AI workflow.
-
Remediate – Use in-built remediation tools to mask, delete or quarantine sensitive data before ingestion, lowering the risk that unmanaged sensitive data will enter the AI model.
-
Control access – Apply access restrictions to limit AI tool access to sensitive data and limit connectors, API permissions, service accounts and retrieval systems following the principle of least privilege.
-
Monitor – AI systems and business processes generate new data all the time, with new stores appearing after AI tools go live. Regular recurring discovery scanning ensures that pipelines remain clean and reduces the risk of unauthorized data access or disclosure.
Safe AI starts with data discovery
AI makes data discovery more urgent for organizations. AI tools make sensitive data easier to retrieve, transform and share, especially when that data already sits in unmanaged or overexposed locations.
By discovering and treating sensitive data before AI tools access it, organizations can reduce the risk of leakage and build safer AI workflows from the start.
Ground Labs Enterprise Recon helps make that possible by giving teams the visibility, remediation and reporting capabilities they need to manage sensitive data before it becomes part of the AI data flow.
“Safe AI adoption starts before the first prompt. It starts with knowing what data you have, where it resides and whether it should be available to AI systems at all.”
Key takeaways
-
AI tools can access sensitive data through prompts, uploads, integrations, APIs, plug-ins and retrieval systems
-
Data leakage often starts before the AI tool itself, when unmanaged sensitive data sits in repositories that AI systems can access
-
Performing data discovery before AI ingestion helps organizations identify, classify and remediate sensitive data before it enters AI workflows
-
Ground Labs Enterprise Recon helps organizations discover, classify, report and remediate sensitive data across complex environments, supporting safer AI adoption
Learn how Ground Labs Enterprise Recon helps discover and reduce sensitive data risk before AI tools can access it, request a demo today